AI
AI
AI
AI
AI
Generative artificial intelligence has experienced a surge of activity in recent months, and OctoML Inc. has been at the forefront of this revolution.
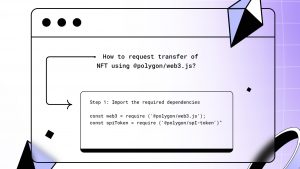
As a leading startup in the field of generative AI, OctoML has just unveiled its OctoAI compute service. The company aims to revolutionize the AI industry by offering developers a fully managed cloud infrastructure that simplifies the process of writing AI applications. OctoAI aims to eliminate complexity and abstract away the heavy lifting involved in deploying models, providing developers with freedom, efficiency and ease of use.
The solution marks a significant milestone in the company’s mission to empower developers and push the boundaries of generative AI. By offering a self-optimizing compute service, OctoML tackles the challenges faced by developers, including the scarcity of GPUs and the confusion surrounding different AI services available in the market.
Jon Turow (pictured, left), partner at Madrona Venture Group, and Luis Ceze (right), co-founder and chief executive officer of OctoML, spoke with theCUBE industry analyst John Furrier during a CUBE Conversation from SiliconANGLE Media’s livestreaming studio. They discussed OctoAI and the implications of generative AI in the industry. [The following conversation has been condensed for clarity.]
Luis, we’ve talked many times about what your role has been in the industry. You have news that you’re announcing today.
Ceze: We are releasing the OctoAI compute service. It’s the first self-optimizing compute service for generative AI. It offers freedom because it allows users to go choose their model or bring their own custom models. Second, it offers efficiency because we optimize the models, choose the right hardware and make sure that it gets the right performance-efficiency tradeoffs. Third, it’s very easy to use. We make it very easy for folks to get started by offering a collection of super-optimized models like Stable Diffusion, LLaMA-based LLMs, Whisper for audio transcription and so on.
There’s a lot of confusion out there around how to get into the generative AI business. I’ve never seen this kind of acceleration. What problem are you solving for the developers?
Ceze: First, by abstracting away the complexity and helping clear this confusion. We offer the ability for developers to come to the platform, select a use case — for example, text-to-image or text-to-text — and very quickly get started with state-of-the-art models ready to go and ready to be integrated into their environment. We also abstract away all of this incredible complexity that is involved in putting a model into production.
Jon, you’ve been covering this area. Madrona, obviously, is an early-stage investor in the company. The world spun right in the front doorstep of OctoML. What’s your assessment? What do you see in this new platform?
Turow: What’s really exciting about the world that we’re in right now is there’s almost sort of an Android moment that Luis and I have written about before. We have very exciting models; you might call them the iPhone kinds of models, things like GPT-4, an AI model from OpenAI, and ChatGPT. You can assemble these models into what are called ensembles, some people call them cocktails, of lots of models that work together. And while that is good and we’ve seen great companies like RunwayML, Midjourney and some others built on top of open-source AI, it’s been difficult to get started with that until now and to manage it and to run it all. What’s exciting about what Octo and Luis and the team are doing is that they’re going to be able to give, for the first time, the kind of ease of use with open-source AI that you’re getting with the closed models. And that’s going to unlock lots of new innovations.
Why use OctoML? What does this mean for me? I want to get in, get my models nailed down. I want to understand how it all fits. I’m tinkering, I’m kicking the tires. How does it work?
Ceze: This topic is obviously near and dear to my heart because of the OctoAI compute service, but also because I’m a computer architect by training. I like seeing chips being so important in this new phase of the world here. What we offer to the developer is the ability to not have to worry about infrastructure. What does this really mean? Because of our ability to deeply optimize the model and how it runs on the actual hardware, we can offer choice. You may not need an A100 and you might use an A10G, for example, or maybe even a T4 that’s readily available. Offering the optimization as such that uses less computes, coupled with the ability to move the work around it and abstract that away from the end user point of view, gives you access to more silicon. That directly leads to more cost efficiencies. Abstracting away the choice of hardware such that users can focus on building their application, which is what really matters, is a significant part of our mission.
Here’s the complete video interview, one of many CUBE Conversations from SiliconANGLE and theCUBE:
THANK YOU